Reinforcement learning is a way of teaching a computer to make decisions by letting it try things and learn from the results. Rather than being given a set of correct answers, the agent figures out what to do on its own through experience.
PPO, which stands for Proximal Policy Optimization, is one of the most popular algorithms for doing this. It is widely used because it is stable, reliable, and works well across a huge range of problems.
The Basic Setup
Before getting into PPO itself, it helps to understand the core pieces of any reinforcement learning problem.
An agent is the thing doing the learning. It exists inside an environment, which is everything around it that it can interact with.
At any given moment, the agent observes the current state of the environment. Based on that state, it chooses an action. The environment then responds with a new state and a reward.
The agent's goal is to take actions that lead to the highest total reward over time.
What is the purpose of a reward in reinforcement learning?
The Policy
The agent makes decisions using something called a policy.
Think of a policy as a rulebook. Given the current state of the world, the policy says what the agent should do. In PPO, and most modern reinforcement learning, the policy is represented by a neural network.
The neural network takes in numbers that describe the current state, and it outputs either a specific action or a set of probabilities for each possible action. The agent then picks based on those probabilities.
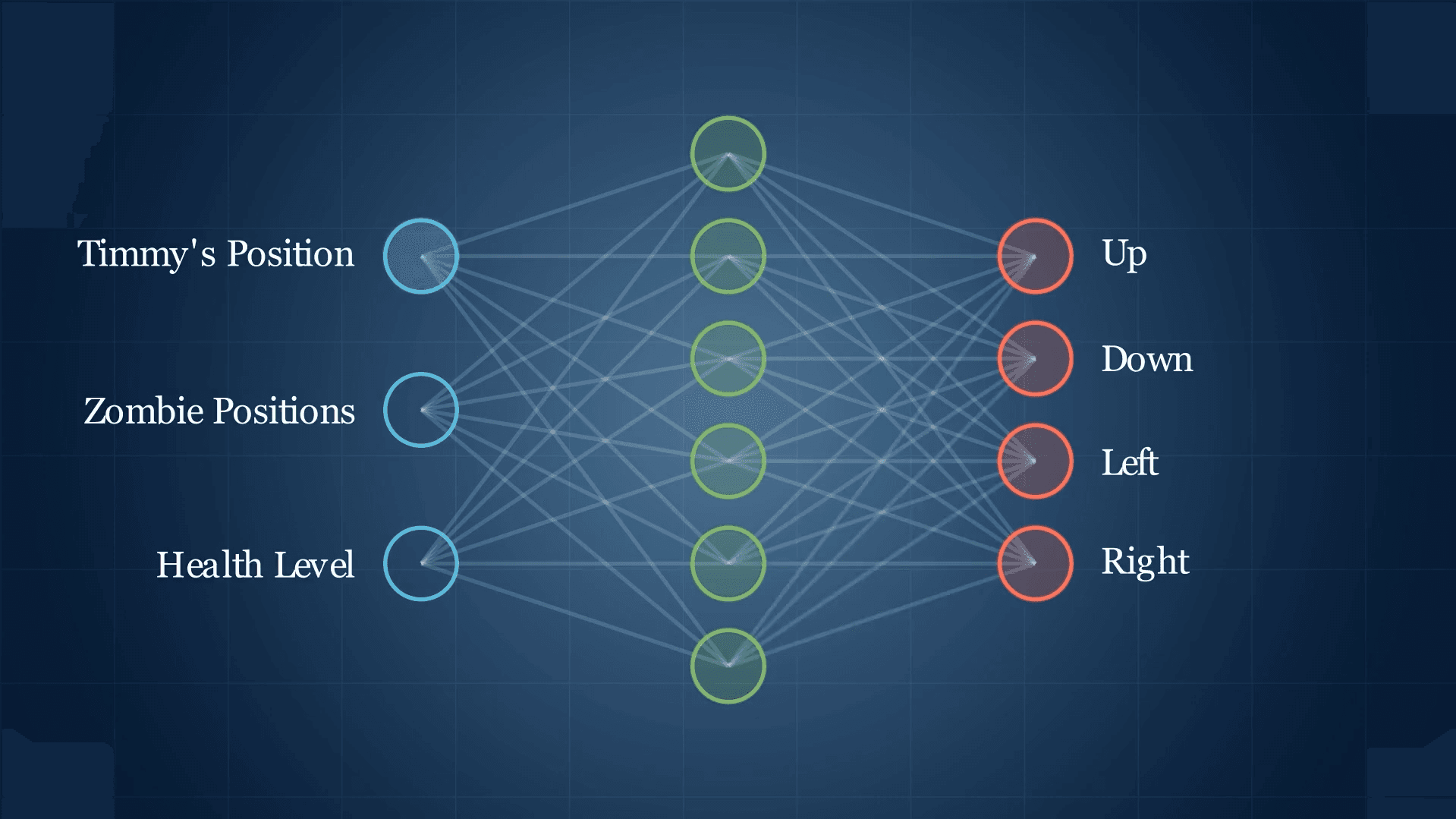
Training the agent means updating the weights inside the neural network so that good actions become more likely over time.
Why Training is Tricky
Updating the policy sounds simple enough, but there is a real risk: if you update the policy too aggressively after a batch of experience, you can accidentally make it much worse and undo everything the agent has learned.
The agent is learning from its own behavior. If the policy changes too much in one step, the experience it just collected is no longer a reliable guide, and the whole training process can collapse.
What is the danger of updating a policy too aggressively?
How PPO Solves This
PPO's core idea is simple: update the policy, but not too much at once.
It does this using a technique called clipping. When PPO calculates how much to update the network, it clips the update if it tries to go too far. The policy is only allowed to move within a small range of where it already is.
This means every training step improves things gradually rather than risking a dramatic change that breaks what is already working.
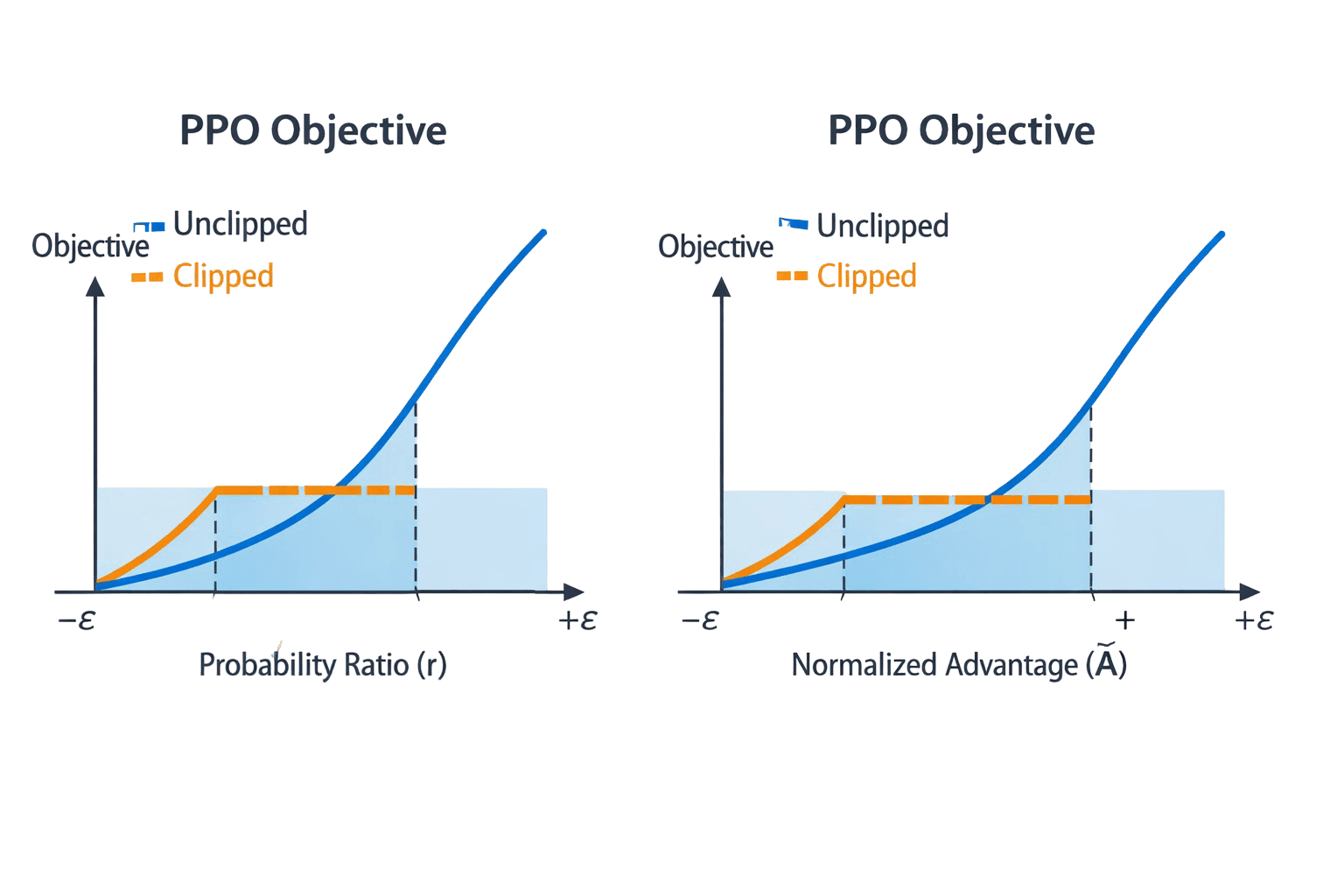
This is the "proximal" in Proximal Policy Optimization. The word proximal means close or nearby. PPO keeps the new policy close to the old one at every step.
Exploration vs Exploitation
A well-trained agent should mostly do things it knows work well. But if it only ever repeats the same moves, it might miss better strategies it has never tried.
This tension is called the exploration vs exploitation tradeoff. Too much exploitation and the agent gets stuck. Too much exploration and it never settles on anything reliable.
PPO handles this by adding an entropy bonus to the training objective. Entropy is a measure of randomness. By rewarding a bit of randomness, PPO nudges the agent to keep exploring rather than always doing the same thing.
What does the entropy bonus in PPO encourage the agent to do?
Valuing Future Rewards
Not all rewards are equal. A reward received right now is more reliable than one that might come later after many more steps. PPO uses a discount factor to reflect this.
A discount factor close to 1 means the agent cares a lot about the future. A discount factor closer to 0 means it focuses mostly on immediate rewards. Most PPO setups use a value somewhere around 0.99, meaning the agent plans ahead but slightly prioritizes what is closer in time.
Measuring How Good an Action Was
To update the policy, PPO needs to know not just whether the agent got a reward, but how much better or worse a specific action was compared to what the agent would have done on average. This is measured using something called the advantage.
Calculating the advantage cleanly is harder than it sounds because rewards are noisy and delayed. PPO uses a technique called Generalized Advantage Estimation (GAE) to produce a cleaner, more stable signal.

Putting It All Together
PPO combines all of these ideas into a single training loop:
- The agent interacts with the environment for a while, collecting experience.
- PPO calculates the advantage of each action taken.
- It updates the policy to make good actions more likely, using clipping to keep the update small.
- The entropy bonus keeps some randomness to encourage exploration.
- The whole process repeats from step one with the updated policy.
Over many thousands or millions of steps, this loop produces an agent that has learned a reliable strategy through nothing but trial, feedback, and careful updating.
Conclusion
Proximal Policy Optimization works by putting guardrails on the learning process. The agent is free to learn from experience, but PPO makes sure each update is small enough not to undo previous progress. Clipping keeps the policy stable, the entropy bonus keeps the agent curious, discounting helps it think ahead, and GAE makes the feedback signal cleaner.
PPO is not the only reinforcement learning algorithm, but it is one of the most widely used because this combination of ideas makes it robust and practical across a wide range of tasks.